Chapter 40 DIY web data
40.1 Interacting with an API
In Chapter 39 we experimented with several packages that “wrapped” APIs. That is, they handled the creation of the request and the formatting of the output. In this chapter we’re going to look at (part of) what these functions were doing.
40.1.1 Load the tidyverse
We will be using the functions from the tidyverse throughout this chapter, so go ahead and load tidyverse package now.
40.1.2 Examine the structure of API requests using the Open Movie Database
First we’re going to examine the structure of API requests via the Open Movie Database (OMDb). OMDb is very similar to IMDb, except it has a nice, simple API. We can go to the website, input some search parameters, and obtain both the XML query and the response from it.
Exercise: determine the shape of an API request. Scroll down to the “Examples” section on the OMDb site and play around with the parameters. Take a look at the resulting API call and the query you get back.
If we enter the following parameters:
title = Interstellar,year = 2014,plot = full,response = JSON
Here is what we see:
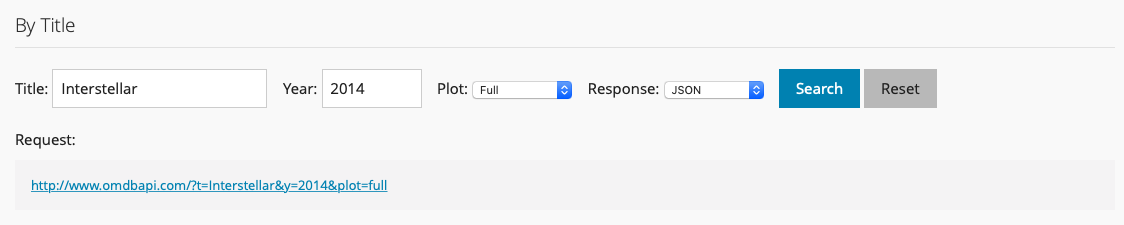
Figure 40.1: Example OMDb Query in JSON
The request URL is:
http://www.omdbapi.com/?t=Interstellar&y=2014&plot=fullNotice the pattern in the request. Let’s try changing the response field from JSON to XML.
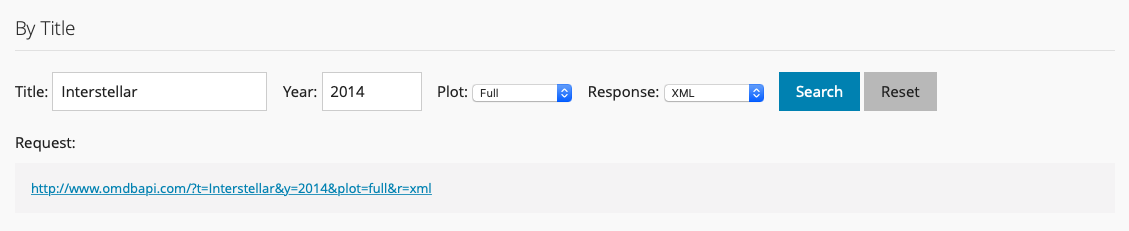
Figure 40.2: Example OMDb Query in XML
Now the request URL is:
http://www.omdbapi.com/?t=Interstellar&y=2014&plot=full&r=xmlTry pasting these URLs into your browser. You should see this if you tried the first URL:
…and this if you tried the second URL (where r=xml):
40.1.3 Create an OMDb API Key
This tells us that we need an API key to access the OMDb API. We will store our key for the OMDb API in our .Renviron file using the helper function edit_r_environ() from the usethis package. Follow these steps:
- Visit this URL and request your free API key: https://www.omdbapi.com/apikey.aspx
- Check your email and follow the instructions to activate your key.
Install/load the usethis package and run
edit_r_environ()in the R Console:- Add
OMDB_API_KEY=<your-secret-key>on a new line, press enter to add a blank line at the end (important!), save the file, and close it.- Note that we use
<your-secret-key>as a placeholder here and throughout these instructions. Your actual API key will look something like:p319s0aa(no quotes or other characters like<or>should go on the right of the=sign).
- Note that we use
- Restart R.
You can now access your OMDb API key from the R console and save it as an object:
#> [1] ""We can use this to easily add our API key to the request URL. Let’s make this API key an object we can refer to as
movie_key:
40.1.3.1 Alternative strategy for keeping keys: .Rprofile
Remember to protect your key! It is important for your privacy. You know, like a key.
Now we follow the rOpenSci tutorial on API keys:
- Add
.Rprofileto your.gitignore!! - Make a
.Rprofilefile (windows tips; mac tips). - Write the following in it:
- Restart R (i.e. reopen your RStudio project).
This code adds another element to the list of options, which you can see by calling options(). Part of the work done by rplos::searchplos() and friends is to go and obtain the value of this option with the function getOption("OMBD_API_KEY"). This indicates two things:
- Spelling is important when you set the option in your
.Rprofile - You can do a similar process for an arbitrary package or key. For example:
## in .Rprofile
options("this_is_my_key" = XXXX)
## later, in the R script:
key <- getOption("this_is_my_key")This is a simple means to keep your keys private, especially if you are sharing the same authentication across several projects.
40.1.3.2 A few timely reminders about your .Rprofile
- It must end with a blank line!
- It lives in the project’s working directory, i.e. the location of your
.Rproj. - It must be gitignored.
Remember that using .Rprofile makes your code un-reproducible. In this case, that is exactly what we want!
40.1.4 Recreate the request URL in R
How can we recreate the same request URLs in R? We could use the glue package to paste together the base URL, parameter labels, and parameter values:
request <- glue::glue("http://www.omdbapi.com/?t=Interstellar&y=2014&plot=short&r=xml&apikey={movie_key}")
request
#> http://www.omdbapi.com/?t=Interstellar&y=2014&plot=short&r=xml&apikey=This works, but it only works for movie titled Interstellar from 2014 where we want the short plot and the XML format. Let’s try to pull out more variables and paste them in with glue:
glue::glue("http://www.omdbapi.com/?t={title}&y={year}&plot={plot}&r={format}&apikey={api_key}",
title = "Interstellar",
year = "2014",
plot = "short",
format = "xml",
api_key = movie_key)
#> http://www.omdbapi.com/?t=Interstellar&y=2014&plot=short&r=xml&apikey=We could go even further and make this into a function called omdb() that we can reuse more easily.
40.1.5 Get data using the curl package
Now we have a handy function that returns the API query. We can paste in the link, but we can also obtain data from within R using the curl package. Install/load the curl package first.
Using curl to get the data in XML format:
request_xml <- omdb(title = "Interstellar", year = "2014", plot = "short",
format = "xml", api_key = movie_key)
con <- curl(request_xml)
answer_xml <- readLines(con, warn = FALSE)
close(con)
answer_xml#> [1] "<?xml version=\"1.0\" encoding=\"UTF-8\"?><root response=\"True\"><movie title=\"Interstellar\" year=\"2014\" rated=\"PG-13\" released=\"07 Nov 2014\" runtime=\"169 min\" genre=\"Adventure, Drama, Sci-Fi\" director=\"Christopher Nolan\" writer=\"Jonathan Nolan, Christopher Nolan\" actors=\"Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow\" plot=\"A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival.\" language=\"English\" country=\"USA, UK, Canada\" awards=\"Won 1 Oscar. Another 43 wins & 143 nominations.\" poster=\"https://m.media-amazon.com/images/M/MV5BZjdkOTU3MDktN2IxOS00OGEyLWFmMjktY2FiMmZkNWIyODZiXkEyXkFqcGdeQXVyMTMxODk2OTU@._V1_SX300.jpg\" metascore=\"74\" imdbRating=\"8.6\" imdbVotes=\"1,333,291\" imdbID=\"tt0816692\" type=\"movie\"/></root>"Using curl to get the data in JSON format:
request_json <- omdb(title = "Interstellar", year = "2014", plot = "short",
format = "json", api_key = movie_key)
con <- curl(request_json)
answer_json <- readLines(con, warn = FALSE)
close(con)
answer_json #> [1] "{\"Title\":\"Interstellar\",\"Year\":\"2014\",\"Rated\":\"PG-13\",\"Released\":\"07 Nov 2014\",\"Runtime\":\"169 min\",\"Genre\":\"Adventure, Drama, Sci-Fi\",\"Director\":\"Christopher Nolan\",\"Writer\":\"Jonathan Nolan, Christopher Nolan\",\"Actors\":\"Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow\",\"Plot\":\"A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival.\",\"Language\":\"English\",\"Country\":\"USA, UK, Canada\",\"Awards\":\"Won 1 Oscar. Another 43 wins & 143 nominations.\",\"Poster\":\"https://m.media-amazon.com/images/M/MV5BZjdkOTU3MDktN2IxOS00OGEyLWFmMjktY2FiMmZkNWIyODZiXkEyXkFqcGdeQXVyMTMxODk2OTU@._V1_SX300.jpg\",\"Ratings\":[{\"Source\":\"Internet Movie Database\",\"Value\":\"8.6/10\"},{\"Source\":\"Rotten Tomatoes\",\"Value\":\"72%\"},{\"Source\":\"Metacritic\",\"Value\":\"74/100\"}],\"Metascore\":\"74\",\"imdbRating\":\"8.6\",\"imdbVotes\":\"1,333,291\",\"imdbID\":\"tt0816692\",\"Type\":\"movie\",\"DVD\":\"31 Mar 2015\",\"BoxOffice\":\"$158,737,441\",\"Production\":\"Paramount Pictures\",\"Website\":\"N/A\",\"Response\":\"True\"}"We have two forms of data that are obviously structured. What are they?
40.2 Intro to JSON and XML
There are two common languages of web services:
- JavaScript Object Notation (JSON)
- eXtensible Markup Language (XML)
Here’s an example of JSON (from this wonderful site):
{
"crust": "original",
"toppings": ["cheese", "pepperoni", "garlic"],
"status": "cooking",
"customer": {
"name": "Brian",
"phone": "573-111-1111"
}
}And here is XML (also from this site):
<order>
<crust>original</crust>
<toppings>
<topping>cheese</topping>
<topping>pepperoni</topping>
<topping>garlic</topping>
</toppings>
<status>cooking</status>
</order>You can see that both of these data structures are quite easy to read. They are “self-describing”. In other words, they tell you how they are meant to be read. There are easy means of taking these data types and creating R objects.
40.2.1 Parsing the JSON response with jsonlite
Our JSON response above can be parsed using jsonlite::fromJSON(). First install/load the jsonlite package.
Parsing our JSON response with fromJSON():
answer_json %>%
fromJSON()
#> $Title
#> [1] "Interstellar"
#>
#> $Year
#> [1] "2014"
#>
#> $Rated
#> [1] "PG-13"
#>
#> $Released
#> [1] "07 Nov 2014"
#>
#> $Runtime
#> [1] "169 min"
#>
#> $Genre
#> [1] "Adventure, Drama, Sci-Fi"
#>
#> $Director
#> [1] "Christopher Nolan"
#>
#> $Writer
#> [1] "Jonathan Nolan, Christopher Nolan"
#>
#> $Actors
#> [1] "Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow"
#>
#> $Plot
#> [1] "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival."
#>
#> $Language
#> [1] "English"
#>
#> $Country
#> [1] "USA, UK, Canada"
#>
#> $Awards
#> [1] "Won 1 Oscar. Another 43 wins & 143 nominations."
#>
#> $Poster
#> [1] "https://m.media-amazon.com/images/M/MV5BZjdkOTU3MDktN2IxOS00OGEyLWFmMjktY2FiMmZkNWIyODZiXkEyXkFqcGdeQXVyMTMxODk2OTU@._V1_SX300.jpg"
#>
#> $Ratings
#> Source Value
#> 1 Internet Movie Database 8.6/10
#> 2 Rotten Tomatoes 72%
#> 3 Metacritic 74/100
#>
#> $Metascore
#> [1] "74"
#>
#> $imdbRating
#> [1] "8.6"
#>
#> $imdbVotes
#> [1] "1,333,291"
#>
#> $imdbID
#> [1] "tt0816692"
#>
#> $Type
#> [1] "movie"
#>
#> $DVD
#> [1] "31 Mar 2015"
#>
#> $BoxOffice
#> [1] "$158,737,441"
#>
#> $Production
#> [1] "Paramount Pictures"
#>
#> $Website
#> [1] "N/A"
#>
#> $Response
#> [1] "True"The output is a named list. A familiar and friendly R structure. Because data frames are lists and because this list has no nested lists-within-lists, we can coerce it very simply:
answer_json %>%
fromJSON() %>%
as_tibble() %>%
glimpse()
#> Observations: 3
#> Variables: 25
#> $ Title <chr> "Interstellar", "Interstellar", "Interstellar"
#> $ Year <chr> "2014", "2014", "2014"
#> $ Rated <chr> "PG-13", "PG-13", "PG-13"
#> $ Released <chr> "07 Nov 2014", "07 Nov 2014", "07 Nov 2014"
#> $ Runtime <chr> "169 min", "169 min", "169 min"
#> $ Genre <chr> "Adventure, Drama, Sci-Fi", "Adventure, Drama, Sci-Fi…
#> $ Director <chr> "Christopher Nolan", "Christopher Nolan", "Christophe…
#> $ Writer <chr> "Jonathan Nolan, Christopher Nolan", "Jonathan Nolan,…
#> $ Actors <chr> "Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, J…
#> $ Plot <chr> "A team of explorers travel through a wormhole in spa…
#> $ Language <chr> "English", "English", "English"
#> $ Country <chr> "USA, UK, Canada", "USA, UK, Canada", "USA, UK, Canad…
#> $ Awards <chr> "Won 1 Oscar. Another 43 wins & 143 nominations.", "W…
#> $ Poster <chr> "https://m.media-amazon.com/images/M/MV5BZjdkOTU3MDkt…
#> $ Ratings <df[,2]> <data.frame[3 x 2]>
#> $ Metascore <chr> "74", "74", "74"
#> $ imdbRating <chr> "8.6", "8.6", "8.6"
#> $ imdbVotes <chr> "1,333,291", "1,333,291", "1,333,291"
#> $ imdbID <chr> "tt0816692", "tt0816692", "tt0816692"
#> $ Type <chr> "movie", "movie", "movie"
#> $ DVD <chr> "31 Mar 2015", "31 Mar 2015", "31 Mar 2015"
#> $ BoxOffice <chr> "$158,737,441", "$158,737,441", "$158,737,441"
#> $ Production <chr> "Paramount Pictures", "Paramount Pictures", "Paramoun…
#> $ Website <chr> "N/A", "N/A", "N/A"
#> $ Response <chr> "True", "True", "True"40.2.2 Parsing the XML response using xml2
We can use the xml2 package to wrangle our XML response.
Parsing our XML response with read_xml():
(xml_parsed <- read_xml(answer_xml))
#> {xml_document}
#> <root response="True">
#> [1] <movie title="Interstellar" year="2014" rated="PG-13" released="07 N ...Not exactly the result we were hoping for! However, this does tell us about the XML document’s structure:
- It has a
<root>node, which has a single child node,<movie>. - The information we want is all stored as attributes (e.g. title, year, etc.).
The xml2 package has various functions to assist in navigating through XML. We can use the xml_children() function to extract all of the children nodes (i.e. the single child, <movie>):
(contents <- xml_contents(xml_parsed))
#> {xml_nodeset (1)}
#> [1] <movie title="Interstellar" year="2014" rated="PG-13" released="07 N ...The xml_attrs() function “retrieves all attribute values as a named character vector”. Let’s use this to extract the information that we want from the <movie> node:
(attrs <- xml_attrs(contents)[[1]])
#> title
#> "Interstellar"
#> year
#> "2014"
#> rated
#> "PG-13"
#> released
#> "07 Nov 2014"
#> runtime
#> "169 min"
#> genre
#> "Adventure, Drama, Sci-Fi"
#> director
#> "Christopher Nolan"
#> writer
#> "Jonathan Nolan, Christopher Nolan"
#> actors
#> "Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow"
#> plot
#> "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival."
#> language
#> "English"
#> country
#> "USA, UK, Canada"
#> awards
#> "Won 1 Oscar. Another 43 wins & 143 nominations."
#> poster
#> "https://m.media-amazon.com/images/M/MV5BZjdkOTU3MDktN2IxOS00OGEyLWFmMjktY2FiMmZkNWIyODZiXkEyXkFqcGdeQXVyMTMxODk2OTU@._V1_SX300.jpg"
#> metascore
#> "74"
#> imdbRating
#> "8.6"
#> imdbVotes
#> "1,333,291"
#> imdbID
#> "tt0816692"
#> type
#> "movie"We can transform this named character vector into a data frame with the help of dplyr::bind_rows():
attrs %>%
bind_rows() %>%
glimpse()
#> Observations: 1
#> Variables: 19
#> $ title <chr> "Interstellar"
#> $ year <chr> "2014"
#> $ rated <chr> "PG-13"
#> $ released <chr> "07 Nov 2014"
#> $ runtime <chr> "169 min"
#> $ genre <chr> "Adventure, Drama, Sci-Fi"
#> $ director <chr> "Christopher Nolan"
#> $ writer <chr> "Jonathan Nolan, Christopher Nolan"
#> $ actors <chr> "Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, J…
#> $ plot <chr> "A team of explorers travel through a wormhole in spa…
#> $ language <chr> "English"
#> $ country <chr> "USA, UK, Canada"
#> $ awards <chr> "Won 1 Oscar. Another 43 wins & 143 nominations."
#> $ poster <chr> "https://m.media-amazon.com/images/M/MV5BZjdkOTU3MDkt…
#> $ metascore <chr> "74"
#> $ imdbRating <chr> "8.6"
#> $ imdbVotes <chr> "1,333,291"
#> $ imdbID <chr> "tt0816692"
#> $ type <chr> "movie"40.3 Introducing the easy way: httr
httr is yet another star in the tidyverse. It is a package designed to facilitate all things HTTP from within R. This includes the major HTTP verbs, which are:
GET()- Fetch an existing resource. The URL contains all the necessary information the server needs to locate and return the resource.POST()- Create a new resource. POST requests usually carry a payload that specifies the data for the new resource.PUT()- Update an existing resource. The payload may contain the updated data for the resource.DELETE()- Delete an existing resource.
HTTP is the foundation for APIs; understanding how it works is the key to interacting with all the diverse APIs out there. An excellent beginning resource for APIs (including HTTP basics) is An Introduction to APIs by Brian Cooksey.
httr also facilitates a variety of authentication protocols.
httr contains one function for every HTTP verb. The functions have the same names as the verbs (e.g. GET(), POST()). They have more informative outputs than simply using curl and come with nice convenience functions for working with the output:
Using httr to get the data in JSON format:
request_json <- omdb(title = "Interstellar", year = "2014", plot = "short",
format = "json", api_key = movie_key)
response_json <- GET(request_json)
content(response_json, as = "parsed", type = "application/json")#> $Title
#> [1] "Interstellar"
#>
#> $Year
#> [1] "2014"
#>
#> $Rated
#> [1] "PG-13"
#>
#> $Released
#> [1] "07 Nov 2014"
#>
#> $Runtime
#> [1] "169 min"
#>
#> $Genre
#> [1] "Adventure, Drama, Sci-Fi"
#>
#> $Director
#> [1] "Christopher Nolan"
#>
#> $Writer
#> [1] "Jonathan Nolan, Christopher Nolan"
#>
#> $Actors
#> [1] "Ellen Burstyn, Matthew McConaughey, Mackenzie Foy, John Lithgow"
#>
#> $Plot
#> [1] "A team of explorers travel through a wormhole in space in an attempt to ensure humanity's survival."
#>
#> $Language
#> [1] "English"
#>
#> $Country
#> [1] "USA, UK, Canada"
#>
#> $Awards
#> [1] "Won 1 Oscar. Another 43 wins & 143 nominations."
#>
#> $Poster
#> [1] "https://m.media-amazon.com/images/M/MV5BZjdkOTU3MDktN2IxOS00OGEyLWFmMjktY2FiMmZkNWIyODZiXkEyXkFqcGdeQXVyMTMxODk2OTU@._V1_SX300.jpg"
#>
#> $Ratings
#> $Ratings[[1]]
#> $Ratings[[1]]$Source
#> [1] "Internet Movie Database"
#>
#> $Ratings[[1]]$Value
#> [1] "8.6/10"
#>
#>
#> $Ratings[[2]]
#> $Ratings[[2]]$Source
#> [1] "Rotten Tomatoes"
#>
#> $Ratings[[2]]$Value
#> [1] "72%"
#>
#>
#> $Ratings[[3]]
#> $Ratings[[3]]$Source
#> [1] "Metacritic"
#>
#> $Ratings[[3]]$Value
#> [1] "74/100"
#>
#>
#>
#> $Metascore
#> [1] "74"
#>
#> $imdbRating
#> [1] "8.6"
#>
#> $imdbVotes
#> [1] "1,333,291"
#>
#> $imdbID
#> [1] "tt0816692"
#>
#> $Type
#> [1] "movie"
#>
#> $DVD
#> [1] "31 Mar 2015"
#>
#> $BoxOffice
#> [1] "$158,737,441"
#>
#> $Production
#> [1] "Paramount Pictures"
#>
#> $Website
#> [1] "N/A"
#>
#> $Response
#> [1] "True"Using httr to get the data in XML format:
request_xml <- omdb(title = "Interstellar", year = "2014", plot = "short",
format = "xml", api_key = movie_key)
response_xml <- GET(request_xml)
content(response_xml, as = "parsed")#> {xml_document}
#> <root response="True">
#> [1] <movie title="Interstellar" year="2014" rated="PG-13" released="07 N ...httr also gives us access to lots of useful information about the quality of our response. For example, the header:
headers(response_xml)
#> $date
#> [1] "Mon, 14 Oct 2019 18:06:33 GMT"
#>
#> $`content-type`
#> [1] "text/xml; charset=utf-8"
#>
#> $`transfer-encoding`
#> [1] "chunked"
#>
#> $connection
#> [1] "keep-alive"
#>
#> $`cache-control`
#> [1] "public, max-age=86400"
#>
#> $expires
#> [1] "Tue, 15 Oct 2019 18:06:33 GMT"
#>
#> $`last-modified`
#> [1] "Mon, 14 Oct 2019 18:06:33 GMT"
#>
#> $vary
#> [1] "*, Accept-Encoding"
#>
#> $`x-aspnet-version`
#> [1] "4.0.30319"
#>
#> $`x-powered-by`
#> [1] "ASP.NET"
#>
#> $`access-control-allow-origin`
#> [1] "*"
#>
#> $`cf-cache-status`
#> [1] "HIT"
#>
#> $age
#> [1] "0"
#>
#> $server
#> [1] "cloudflare"
#>
#> $`cf-ray`
#> [1] "525b7ce4dd7cc568-ORD"
#>
#> $`content-encoding`
#> [1] "gzip"
#>
#> attr(,"class")
#> [1] "insensitive" "list"And also a handy means to extract specifically the HTTP status code:
In fact, we didn’t need to create omdb() at all. httr provides a straightforward means of making an HTTP request with the query argument:
the_martian <- GET("http://www.omdbapi.com/?",
query = list(t = "The Martian", y = 2015, plot = "short",
r = "json", apikey = movie_key))
content(the_martian)#> $Title
#> [1] "The Martian"
#>
#> $Year
#> [1] "2015"
#>
#> $Rated
#> [1] "PG-13"
#>
#> $Released
#> [1] "02 Oct 2015"
#>
#> $Runtime
#> [1] "144 min"
#>
#> $Genre
#> [1] "Adventure, Drama, Sci-Fi"
#>
#> $Director
#> [1] "Ridley Scott"
#>
#> $Writer
#> [1] "Drew Goddard (screenplay by), Andy Weir (based on the novel by)"
#>
#> $Actors
#> [1] "Matt Damon, Jessica Chastain, Kristen Wiig, Jeff Daniels"
#>
#> $Plot
#> [1] "An astronaut becomes stranded on Mars after his team assume him dead, and must rely on his ingenuity to find a way to signal to Earth that he is alive."
#>
#> $Language
#> [1] "English, Mandarin"
#>
#> $Country
#> [1] "UK, USA, Hungary"
#>
#> $Awards
#> [1] "Nominated for 7 Oscars. Another 37 wins & 185 nominations."
#>
#> $Poster
#> [1] "https://m.media-amazon.com/images/M/MV5BMTc2MTQ3MDA1Nl5BMl5BanBnXkFtZTgwODA3OTI4NjE@._V1_SX300.jpg"
#>
#> $Ratings
#> $Ratings[[1]]
#> $Ratings[[1]]$Source
#> [1] "Internet Movie Database"
#>
#> $Ratings[[1]]$Value
#> [1] "8.0/10"
#>
#>
#> $Ratings[[2]]
#> $Ratings[[2]]$Source
#> [1] "Rotten Tomatoes"
#>
#> $Ratings[[2]]$Value
#> [1] "91%"
#>
#>
#> $Ratings[[3]]
#> $Ratings[[3]]$Source
#> [1] "Metacritic"
#>
#> $Ratings[[3]]$Value
#> [1] "80/100"
#>
#>
#>
#> $Metascore
#> [1] "80"
#>
#> $imdbRating
#> [1] "8.0"
#>
#> $imdbVotes
#> [1] "695,039"
#>
#> $imdbID
#> [1] "tt3659388"
#>
#> $Type
#> [1] "movie"
#>
#> $DVD
#> [1] "12 Jan 2016"
#>
#> $BoxOffice
#> [1] "$202,313,768"
#>
#> $Production
#> [1] "20th Century Fox"
#>
#> $Website
#> [1] "N/A"
#>
#> $Response
#> [1] "True"With httr, we are able to pass in the named arguments to the API call as a named list. We are also able to use spaces in movie names; httr encodes these in the URL before making the GET request.
It is very good to learn your HTTP status codes.
The documentation for httr includes a vignette of “Best practices for writing an API package”, which is useful for when you want to bring your favourite web resource into the world of R.
40.4 Scraping
What if data is present on a website, but isn’t provided in an API at all? It is possible to grab that information too. How easy that is to do depends a lot on the quality of the website that we are using.
HTML is a structured way of displaying information. It is very similar in structure to XML (in fact many modern html sites are actually XHTML5, which is also valid XML).
](https://imgs.xkcd.com/comics/tags.png)
Figure 40.3: From xkcd
Two pieces of equipment:
- The rvest package (CRAN; GitHub). Install via
install.packages("rvest)". - SelectorGadget: point and click CSS selectors. Install in your browser.
Before we go any further, let’s play a game together!
40.4.1 Obtain a table
Let’s make a simple HTML table and then parse it.
- Make a new, empty project
- Make a totally empty
.Rmdfile and save it as"GapminderHead.Rmd" - Copy this into the body:
---
output: html_document
---
```{r echo=FALSE, results='asis'}
library(gapminder)
knitr::kable(head(gapminder))
```Knit the document and click “View in Browser”. It should look like this:
| country | continent | year | lifeExp | pop | gdpPercap |
|---|---|---|---|---|---|
| Afghanistan | Asia | 1952 | 28.8 | 8425333 | 779 |
| Afghanistan | Asia | 1957 | 30.3 | 9240934 | 821 |
| Afghanistan | Asia | 1962 | 32.0 | 10267083 | 853 |
| Afghanistan | Asia | 1967 | 34.0 | 11537966 | 836 |
| Afghanistan | Asia | 1972 | 36.1 | 13079460 | 740 |
| Afghanistan | Asia | 1977 | 38.4 | 14880372 | 786 |
We have created a simple HTML table with the head of gapminder in it! We can get our data back by parsing this table into a data frame again. Extracting data from HTML is called “scraping”, and we can do it in R with the rvest package:
#> [[1]]
#> country continent year lifeExp pop gdpPercap
#> 1 Afghanistan Asia 1952 28.8 8425333 779
#> 2 Afghanistan Asia 1957 30.3 9240934 821
#> 3 Afghanistan Asia 1962 32.0 10267083 853
#> 4 Afghanistan Asia 1967 34.0 11537966 836
#> 5 Afghanistan Asia 1972 36.1 13079460 740
#> 6 Afghanistan Asia 1977 38.4 14880372 78640.5 Scraping via CSS selectors
Let’s practice scraping websites using our newfound abilities. Here is a table of research publications by country.
](img/pubs.png)
Figure 40.4: From Scimago Journal & Country Rank
We can try to get this data directly into R using read_html() and html_table():
If you look at the structure of research (i.e. via str(research)) you’ll see that we’ve obtained a list of data.frames. The top of the page contains another table element. This was also scraped!
Can we be more specific about what we obtain from this page? We can, by highlighting that table with CSS selectors:
research <- read_html("http://www.scimagojr.com/countryrank.php") %>%
html_node(".tabla_datos") %>%
html_table()
glimpse(research)
#> Observations: 239
#> Variables: 9
#> $ `` <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, …
#> $ Country <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
#> $ Country <chr> "United States", "China", "United Kingd…
#> $ Documents <int> 12070144, 5901404, 3449243, 3019959, 27…
#> $ `Citable documents` <int> 10701848, 5785424, 2935537, 2787096, 26…
#> $ Citations <int> 297655815, 48833849, 77355297, 61262766…
#> $ `Self-Citations` <int> 134368758, 27480980, 17558272, 14946684…
#> $ `Citations per Document` <dbl> 24.66, 8.27, 22.43, 20.29, 15.55, 19.91…
#> $ `H index` <int> 2222, 794, 1373, 1203, 967, 1094, 1102,…40.6 Random observations on scraping
- Make sure you’ve obtained ONLY what you want! Scroll over the whole page to ensure that SelectorGadget hasn’t found too many things.
- If you are having trouble parsing, try selecting a smaller subset of the thing you are seeking (e.g. being more precise).
MOST IMPORTANTLY confirm that there is NO rOpenSci package and NO API before you spend hours scraping (the API was right here).
40.7 Extras
40.7.1 Airports
First, go to this website about Airports. Follow the link to get your API key (you will need to click a confirmation email).
List of all the airports on the planet:
https://airport.api.aero/airport/?user_key={yourkey}List of all the airports matching Toronto:
https://airport.api.aero/airport/match/toronto?user_key={yourkey}The distance between YVR and LAX:
https://airport.api.aero/airport/distance/YVR/LAX?user_key={yourkey}Do you need just the US airports? This API does that (also see this) and is free.